
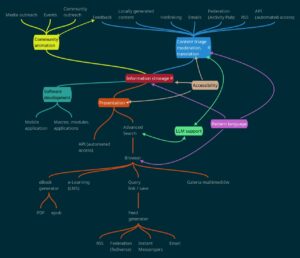
The Looking Up! platform, understood as a package (stack) of cooperating applications, essentially has three main tasks:
- Storing information in the form of standard units, containing diverse content, linked among themselves by a network of logical relationships.
- Introducing new units, containing content delivered through established channels from selected sources. The introduction of content includes its classification, moderation and possible translation or transcription.
- Presentation (sharing) of information, using a variety of channels (interfaces), as illustrated in the platform map.
The above tasks will be the subject of prototyping in the first phase of the “Looking Up” programme. The following activities will be gradually introduced from the implementation phase on.
- Animating and interacting with the media, the online user community and the “on the ground” communities, organizing hackathons, edutons and other inclusive and supportive events.
- Ensuring accessibility (in the sense of WCAG) of software and information published on the platform.
- Building a pattern language as a specialized taxonomy, focused on the semi-automatic generation of complex solutions (in the broad sense) of technology, based on information stored on the platform.
- Experimental implementation of LLM (large-scale language model) as an assistant in search and selection of information for user needs.
Below you will find the content of the functional platform map in text form, with additional comments.
Information entry
Content triage, moderation, translation.
Essentially, it means transforming raw input data into structured content, logically added to an existing network of relationships.
We will define the attributes of the content unit (entry, article) and determine their values so that they can be used for filtering in output channels.
We will define a relationship dictionary to build the structure of a “semantic wiki.”
We also need an efficient translation system to effectively absorb information from different sources.
Input channels
- Locally created content.
- Dynamic links.
- Emails.
- Federation (Activity Pub – fediverse).
- RSS / Atom.
- Feedback from users.
Information storage
In the form of related entries (articles) and systematics organizing relationships. The working assumption is a wiki structure, providing a basic presentation of information in a way familiar to users. At the moment, the most serious candidate is https://xwiki.org, due to its modular design, open architecture and numerous additional modules in line with our needs.
Information access / presentation
The presentation of information is closely linked to the project’s three goals of education, information and inspiration, discussed separately. The basis for its effectiveness will be a precise search, ultimately supported by the LLM model. The search results will then be fed into an output channel viewer. Regardless of the browser, there will also be automated access via an API.
Output channels
- eBook generator.
- Linking/saving of search results.
- Multimedia gallery.
- Feed generator.
- RSS / Atom.
- Federation (Activity Pub).
- Email.
- Communicators.
- e-Learning (LMS).
Additional tasks
Software development
Provide an environment for the development and launch of new software. Development of the platform will require the creation of specialized modules as needs arise.
Accessibility assurance
An independent project to ensure and oversee compliance with WCAG guidelines for accessibility of data and software for people with limitations. From the data entry stage to the presentation form, all elements will be reviewed and optimized in this regard.
Pattern language
A design pattern is a universal, field-proven solution to common, recurring design problems. A pattern language is a structured collection of patterns, defining their content (functions), requirements, and how to combine them into meaningful aggregates.
Large Language Model
A large language model is a kind of machine learning model that has been trained on huge text datasets and can generate text based on the context given to it. We hope to use this technology to support information search and selection on the platform to better meet the needs of users.