
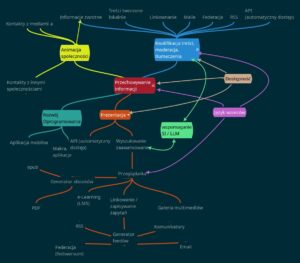
Platforma PwG, rozumiana jako pakiet (stack) współpracujących aplikacji ma zasadniczo trzy główne zadania:
- Przechowywanie informacji w postaci standardowych jednostek, zawierających zróżnicowane treści, powiązanych między sobą siecią logicznych relacji.
- Wprowadzanie nowych jednostek, zawierających treści dostarczone ustalonymi kanałami z wybranych źródeł. Wprowadzanie treści obejmuje ich klasyfikację, moderacją i ewentualne tłumaczenie lub transkrypcję.
- Prezentację (udostępnianie) informacji, z wykorzystaniem różnorakich kanałów (interfejsów), jak zilustrowano na mapie platformy.
Powyższe zadania będą przedmiotem prototypowania w pierwszej fazie programu „Patrzymy w Górę”. Poniższe działania będą stopniowo wprowadzane od fazy implementacji.
- Animacji i kontaktów z mediami, społecznością użytkowników online i społecznościami „w terenie”, organizowania hakatonów, edutonów i innych wydarzeń integrujących i wspomagających.
- Zapewnienia dostępności (w rozumieniu WCAG) oprogramowania i informacji opublikowanej na platformie.
- Budowy języka wzorców, jako wyspecjalizowanej taksonomii, skoncentrowanej na półautomatycznym generowaniu kompleksowych rozwiązań (w szerokim rozumieniu) technicznych, na podstawie informacji przechowywanej na platformie.
- Eksperymentalnej implementacji LLM (wielkiego modelu językowego) jako asystenta w wyszukiwaniu i doborze informacji do potrzeb użytkownika.
Poniżej znajdziesz zawartość funkcjonalnej mapy platformy w formie tekstowej, z dodatkowymi komentarzami.
Wprowadzanie danych
Kwalifikacja treści, moderacja, tłumaczenia.
Ogólnie rzecz biorąc, oznacza to przekształcanie surowych danych wejściowych w ustrukturyzowaną treść, w logiczny sposób dodawaną do istniejącej już sieci powiązań.
Zdefiniujemy atrybuty jednostki treści (wpisu, artykułu) i ustalić ich wartości, aby można je było wykorzystać do filtrowania w kanałach wyjściowych.
Będziemy definiować słownik relacji, aby zbudować strukturę „semantycznej wiki”.
Potrzebujemy też wydajnego systemu tłumaczenia, aby skutecznie absorbować informacje z różnych źródeł.
Kanały wejściowe
- Treści tworzone lokalnie.
- Dynamiczne linki.
- Maile.
- Federacja (Activity Pub – fediwersum).
- RSS / Atom.
- Informacje zwrotne od użytkowników.
Przechowywanie informacji
W postaci powiązanych ze sobą wpisów (artykułów) i systematyk porządkujących relacje. Roboczym założeniem jest struktura wiki, zapewniająca podstawową prezentację informacji w znany użytkownikom sposób. W tej chwili najpoważniejszym kandydatem jest DokuWiki, ze względu na modułową konstrukcję, otwartą architekturę i liczne moduły dodatkowe zgodne z naszymi potrzebami.
Prezentacja informacji
Prezentacja informacji jest ściśle powiązana z trzema celami projektu: edukacją, informacją i inspiracją, omówionymi osobno. Podstawą jej skuteczności będzie precyzyjne wyszukiwanie, docelowo wspomagane modelem LLM. Wyniki wyszukiwania będą następnie przekazywane do przeglądarki kanałów wyjściowych. Niezależnie od przeglądarki, będzie też możliwy zautomatyzowany dostęp poprzez API.
Kanały wyjściowe
- Generator ebooków.
- Linkowanie / zapisywanie wyników wyszukiwania.
- Galeria multimediów.
- Generator feedów.
- RSS / Atom.
- Federacja (Activity Pub).
- Email.
- Komunikatory.
- e-Learning (LMS).
Zadania dodatkowe
Rozwój oprogramowania
Zapewnienie środowiska dla potrzeb rozwoju i uruchamiania nowego oprogramowania. Rozwój platformy będzie wymagał stworzenia specjalistycznych modułów, w miarę pojawiających się potrzeb.
Zapewnienie dostępności
Niezależny projekt, którego celem będzie zapewnienie i nadzorowanie zgodności z wytycznymi WCAG, dotyczącymi dostępności danych i oprogramowania dla osób z ograniczeniami. Od etapu wprowadzenia danych, aż do formy prezentacji, wszystkie elementy będą weryfikowane i optymalizowane pod tym względem.
Język wzorów
Wzorzec projektowy to uniwersalne, sprawdzone w praktyce rozwiązanie często pojawiających się, powtarzalnych problemów projektowych. Język wzorców to ich uporządkowany zbiór, określający ich treść (funkcje), wymagania, i sposób łączenia ich w sensowne większe całości.
Model językowy
Wielki model językowy to to rodzaj modelu uczenia maszynowego (Machine Learning), który został wytrenowany na ogromnych zbiorach danych tekstowych i potrafi generować tekst na podstawie podanego mu kontekstu. Mamy nadzieję użyć tej technologii do wspomagania wyszukiwania i selekcji informacji na platformie, aby jak najlepiej zaspokoić potrzeby użytkowników.